I’m building a simplified sync engine from scratch using Nuxt 4. My approach: study how production-grade frameworks solve the hard problems, then implement a minimal version myself.
Jazz is my primary reference a local-first framework with elegant patterns for persistence, conflict resolution, and cross-tab sync. Rather than reading through their codebase manually, I use Claude Code to research, extract patterns, and help me implement them.
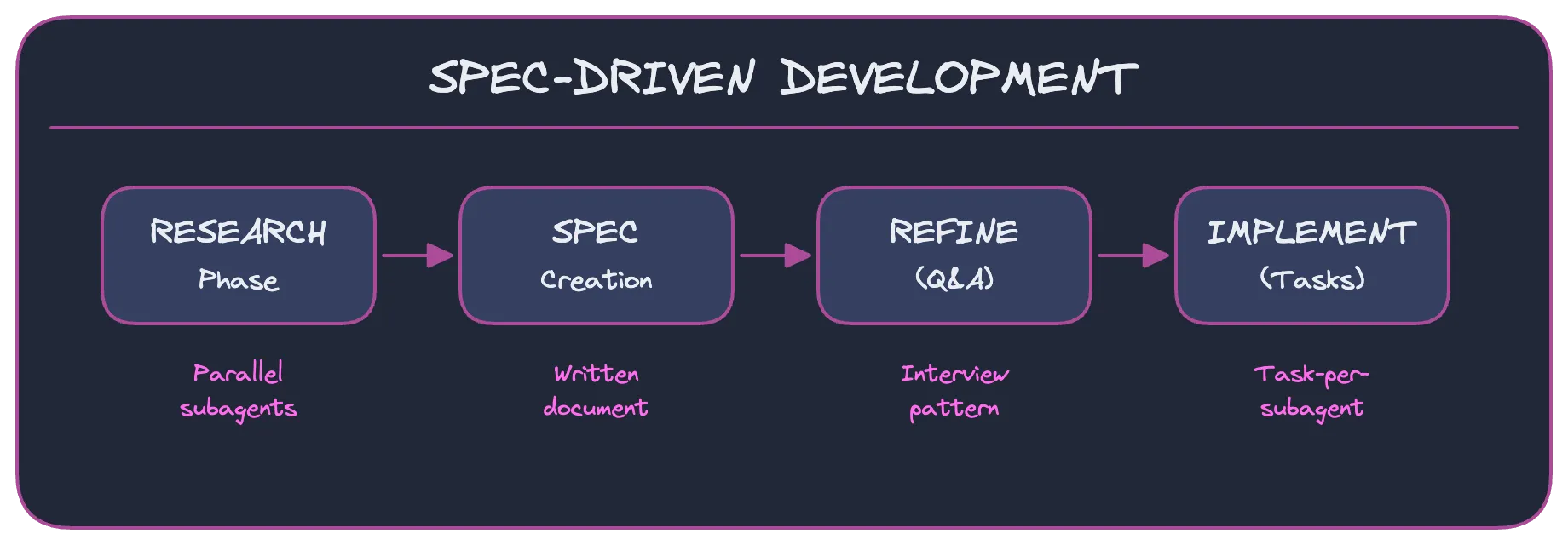
This post documents the workflow I call Spec-Driven Development with Claude Code the exact prompts, tools, and patterns I used to migrate my storage layer from SQLite/WASM to IndexedDB in a single day.
The Problem
My sync engine was using sql.js (SQLite compiled to WASM) for client-side storage. It worked, but had issues:
- Large WASM bundle (~1MB)
- Complex COOP/COEP header requirements
- No native cross-tab sync
I wanted to migrate to IndexedDB, borrowing patterns from Jazz. But this was a significant refactor touching 15+ files. (For background on local-first web development What is Local-first Web Development? What is local-first software and why does it matter? This guide covers local-first architecture, offline-capable apps with automatic sync, data ownership, and how to build a local-first web app with Vue step by step. and why it matters, see my earlier post.)
The Workflow
Instead of diving into code, I used Claude Code as an AI development teamwith myself as the product owner, Claude as the tech lead, and subagents as developers.
Important: I also cloned the source code of Jazz into my Project so Claude could reference it during research and implementation.
Phase 1: Research with Parallel Subagents
The Prompt
you have access to jazz source repo explain to me how they use indexdb in the client to persist state our project is using sqlite but we want to change to indexdb with jazz your goal is to write a report spin up multiple subagents for your research task
What Happened
Claude spawned 5 parallel research agents, each investigating a specific aspect of Jazz:
No custom agents needed
These are Claude Code’s built-in subagents. The Task tool is a native tool in Claude Code, just like Read or Bash. When you ask Claude to “spin up subagents,” it uses this built-in tool automatically with the general-purpose subagent type. No custom agent definition or setup is required.
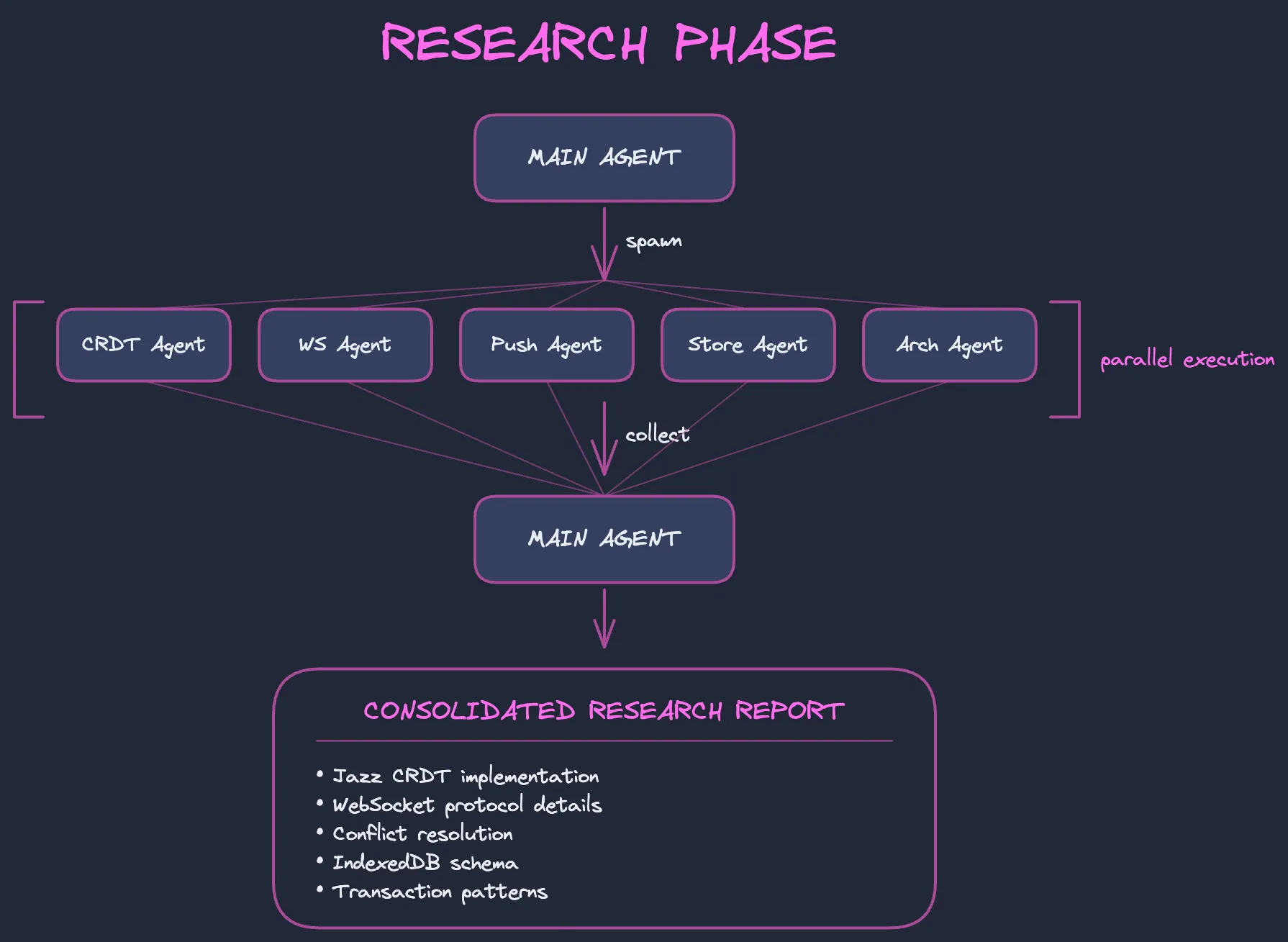
Each agent explored the Jazz codebase independently and reported back:
| Agent | Focus | Key Findings |
|---|---|---|
| CRDT | Data structures | CoMap, CoList use operation-based CRDTs with LWW |
| WebSocket | Real-time sync | 4-message protocol: load, known, content, done |
| Push/Pull | Sync strategy | Hybrid model with known-state tracking |
| Storage | Persistence | IndexedDB with coValues, sessions, transactions stores |
| Architecture | Overall design | Monorepo with platform adapters |
Follow-up Prompt
research longer and improve the plan
This triggered deeper investigation into edge cases and implementation details.
Phase 2: Spec Creation
After research, Claude wrote a comprehensive technical specification to docs/indexeddb-migration-spec.md:
Full spec
# IndexedDB Migration Specification
## Part 1: How Jazz Uses IndexedDB
- Database schema (coValues, sessions, transactions stores)
- Transaction queuing pattern
- Entity caching layer
- Session-based conflict resolution
## Part 2: Current SQLite Architecture Analysis
- sql.js WASM setup
- Existing sync protocol
- Pain points and limitations
## Part 3: Migration Plan (4 Phases)
- Phase 1: Core IndexedDB utilities
- Phase 2: Composables layer
- Phase 3: Cross-tab sync
- Phase 4: Cleanup and testing
## Part 4: Implementation Checklist
- [ ] idb-helpers.ts
- [ ] useIndexedDB.ts
- [ ] useSessionTracking.ts
- ... (14 items total)Key insight: The spec becomes the source of truth. It’s a document Claude can reference during implementation, ensuring consistency across all tasks. It also becomes a Pin that we can use if something went wrong during implementation.
Phase 3: Spec Refinement via Interview
Before implementation, I wanted to ensure the spec was solid. I used Claude’s AskUserQuestion tool:
The Prompt
use the ask_user_question tool do you have any questions regarding @docs/indexeddb-migration-spec.md before we implement it we want to improve the specs
Claude asked clarifying questions:
- Should we support migration from existing SQLite data?
- What’s the preferred conflict resolution strategy?
- Should cross-tab sync use BroadcastChannel or SharedWorker?
After answering, I requested Vue-specific improvements:
we want to use provide and inject you have access to the source code of pinia spin up multiple subagents how they do it so we can use same patterns
Claude researched Pinia’s patterns and updated the spec with:
- Symbol-based injection keys
- Provider composables with fallback patterns
- Proper cleanup on unmount
Phase 4: Implementation with Task Delegation
This is where the new Claude Code Task System shines. (If you’re unfamiliar with subagents and how they work in Claude Code, my customization guide Claude Code Customization: CLAUDE.md, Slash Commands, Skills, and Subagents The complete guide to customizing Claude Code. Compare CLAUDE.md, slash commands, skills, and subagents with practical examples showing when to use each. covers the fundamentals.)
The Prompt
implement @docs/indexeddb-migration-spec.md use the task tool and each task should only be done by a subagent so that context is clear after each task do a commit before you continue you are the main agent and your subagents are your devs
Understanding Claude Code’s Task System
Claude Code’s task systeminspired by Beads, Steve Yegge’s distributed git-backed issue trackersolves two critical problems with AI coding agents:
Agent Amnesia: Starting a new session mid-task loses all progress unless you manually document remaining work.
Context Pollution: A full context window makes the agent drop discovered bugs instead of tracking them.
The previous todo list lived in session memory and vanished on restart. The new task system persists tasks to disk, making them shareable across sessions and subagents.
How Tasks Persist
Tasks are stored in .claude/tasks/{session-id}/ as JSON files:
{
"id": "task-1",
"subject": "Create idb-helpers.ts",
"description": "Implement IndexedDB promise wrappers...",
"status": "pending | in_progress | completed",
"blocks": ["task-3", "task-4"],
"blockedBy": ["task-0"]
}The Four Task Tools
| Tool | Purpose |
|---|---|
TaskCreate | Create a new task with subject, description, and dependencies |
TaskUpdate | Update status (pending → in_progress → completed) or modify dependencies |
TaskList | View all tasks, their status, and what’s blocked |
TaskGet | Get full details of a specific task including description |
Task System Architecture
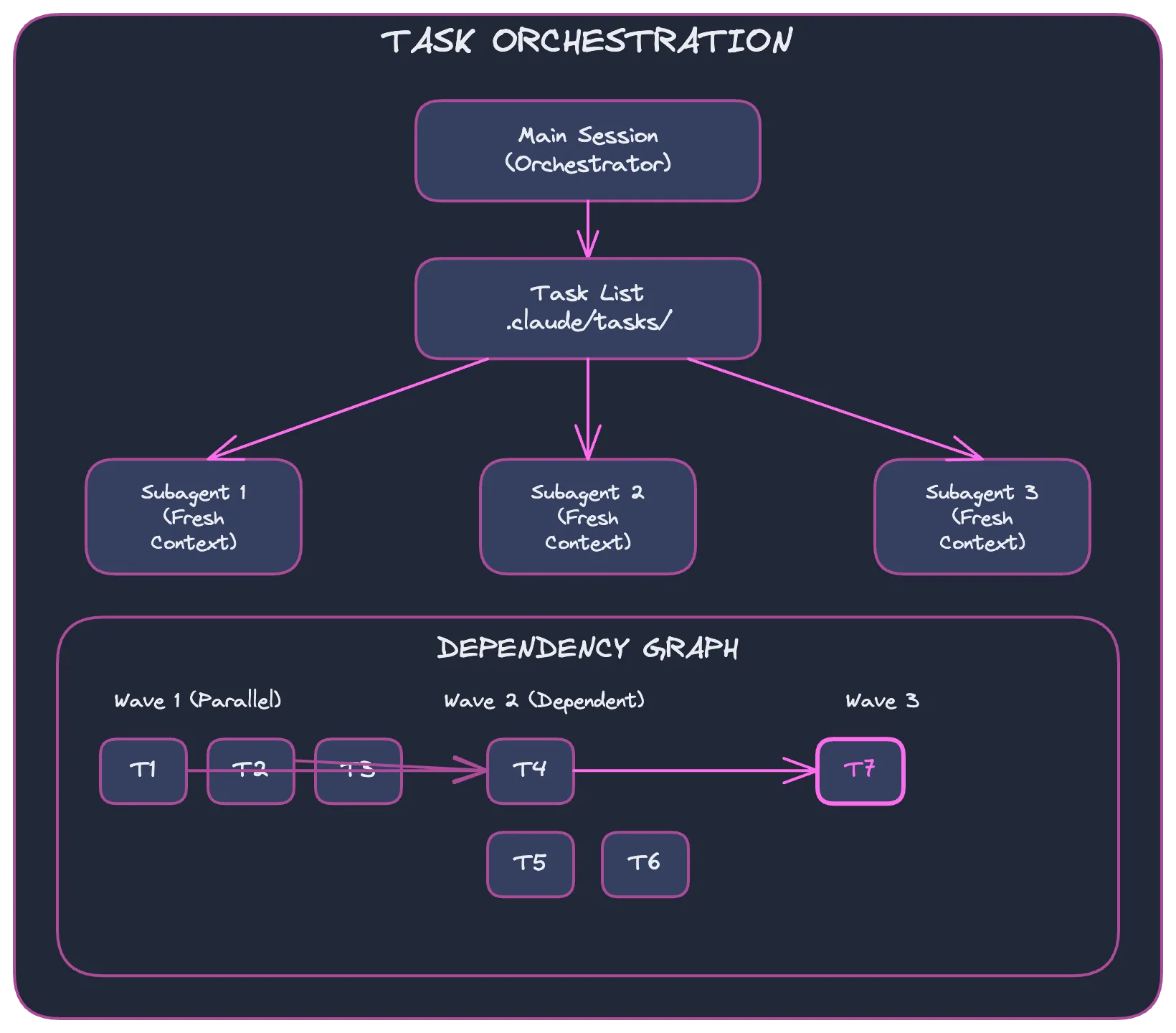
Why Subagents + Tasks = Context Efficiency
By delegating each task to a subagent, the main session stays leanit only handles orchestration (creating tasks, tracking progress, committing). Each subagent gets a fresh context window focused entirely on its specific task, reads what it needs, implements, and returns. This means the main agent won’t run out of context even for larger refactors with dozens of tasks.
For truly massive projects spanning days or weeks, a full autonomous agent like Ralph would be more appropriate. Ralph is elegantly simplea bash loop that feeds a markdown file into Claude Code repeatedly:
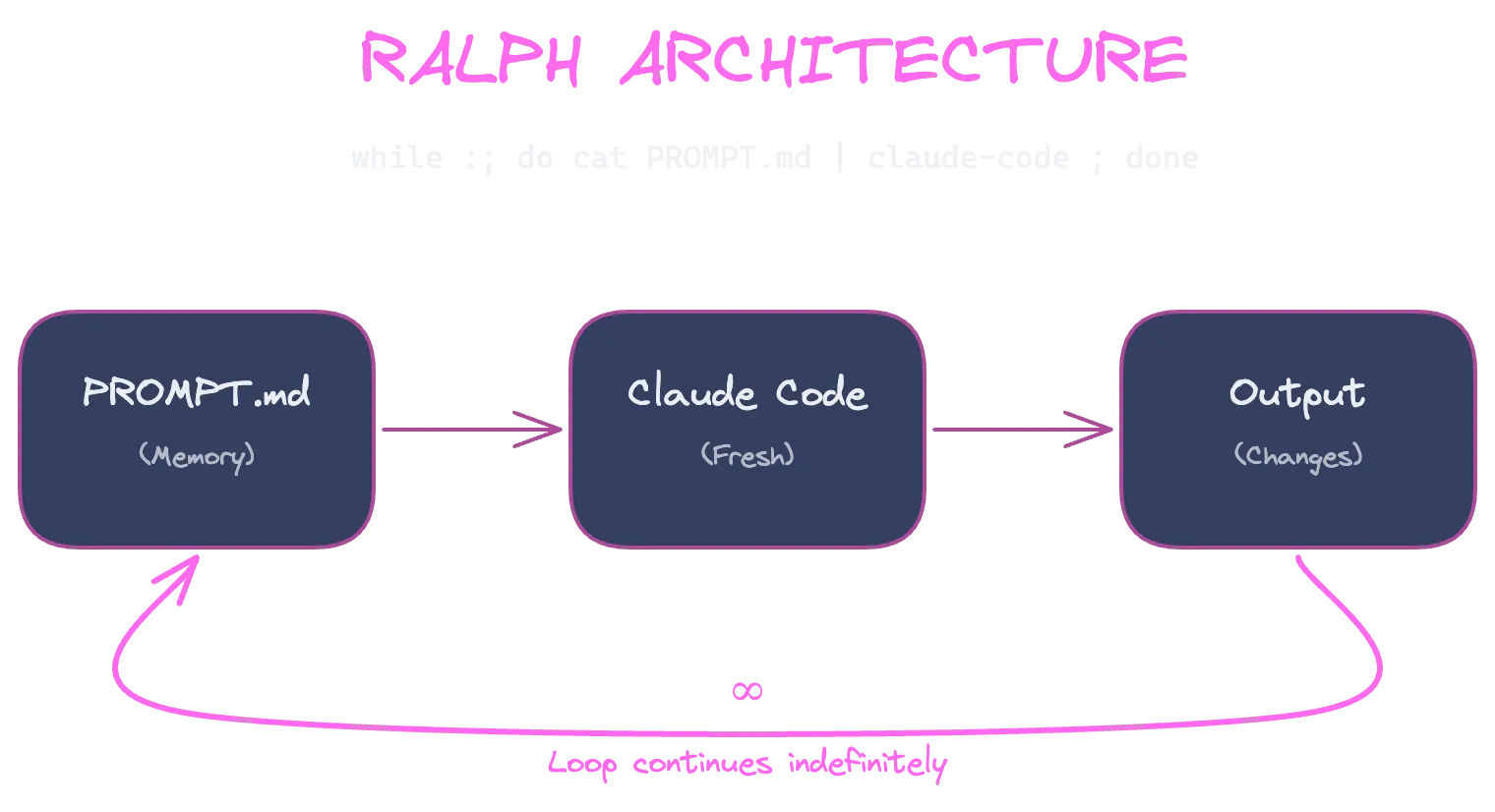
The key difference: Ralph executes each iteration in a completely new Claude session, using the markdown file as the only persistent memory. This makes it truly stateless and capable of running for days.
This spec-driven approach hits a middle ground: subagents get fresh context but the main orchestrator maintains state within a single session. Structured enough to maintain coherence, flexible enough to handle complexity, without the setup overhead of a full autonomous system.
The Execution Flow
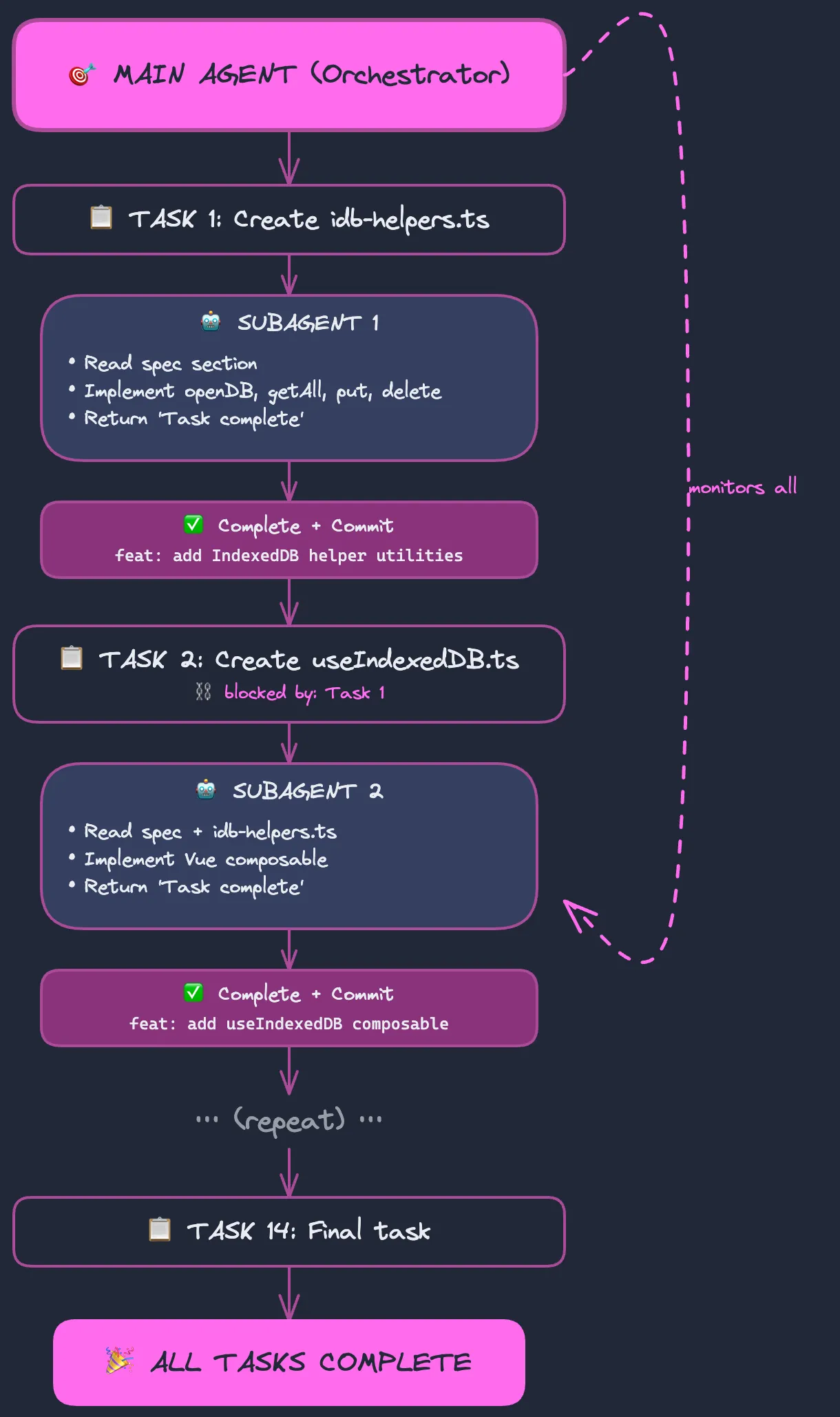
Why This Pattern Works
- Context isolation: Each subagent starts fresh, reading only what it needsno accumulated cruft
- Persistent progress: Tasks survive session restarts; pick up where you left off
- Dependency-aware parallelism: Claude identifies which tasks can run concurrently
- Atomic commits: Every task = one commit, making rollbacks trivial
- Spec as contract: Subagents reference the spec, ensuring consistency
Backpressure: Let the System Catch Mistakes
One crucial element that makes atomic commits powerful: backpressure. Instead of manually reviewing every change, set up pre-commit hooks that run tests, linting, and type checking automatically.
# .husky/pre-commit
pnpm typecheck && pnpm lint && pnpm test-runWhen a subagent commits, the hook runs immediately. If tests fail, the commit is rejected and the agent sees the error outputgiving it a chance to self-correct before moving on. This creates automated feedback that catches issues at the source rather than accumulating bugs across multiple tasks.
The result: you stop being the bottleneck for quality control. The system validates correctness while you focus on higher-level decisions.
When Things Go Wrong
The first execution wasn’t perfectI started the project and hit some errors. But here’s where the spec pays off: I opened a new chat, pinned the spec document, pasted the error, and Claude fixed it immediately. No context rebuilding, no re-explaining the architecture.
The spec acts as a recovery point. When a session goes sideways or context gets polluted, you don’t lose everythingyou have a document that captures the full intent and design decisions.
The Results
After ~45 minutes:
$ git log-oneline | head20
9dc1c96 refactor: clean up code structure
9fce16b feat(storage): migrate from SQLite to IndexedDB
835c494 feat: integrate IDB sync engine provider
d2cd7b7 refactor: remove SQLite/sql.js dependencies
2fb7656 feat: add browser mode test stubs
... (14 commits total)14 tasks completed, 14 commits, 15+ files changed, one PR ready for review. See the full pull request (includes additional manual changes).
And despite orchestrating 14 subagents, the main session’s context stayed manageable:
This proves the delegation pattern worksthe main agent handled orchestration while subagents did the heavy lifting in isolated contexts.
The Prompt Patterns
Here are the key prompt patterns that make this workflow effective:
1. Parallel Research
spin up multiple subagents for your research task
Triggers Claude to spawn parallel agents, each investigating independently. Much faster than sequential research.
2. Spec-First Development
your goal is to write a report/document
Forces Claude to produce a written artifact before any code. This becomes the source of truth.
3. Interview Before Implementation
use the ask_user_question tool… before we implement
Surfaces ambiguities and design decisions before they become bugs.
4. Task Delegation with Commits
use the task tool and each task should only be done by a subagent after each task do a commit before you continue
Creates the orchestration pattern with atomic commits.
5. Role Assignment
you are the main agent and your subagents are your devs
Sets expectations for how Claude should behaveas a coordinator, not a solo implementer.
Comparison: Traditional vs Spec-Driven
| Traditional AI Coding | Spec-Driven Development | |
|---|---|---|
| Flow | Prompt → Code → Debug → Repeat | Research → Spec → Refine → Tasks → Done |
| Context | Fills up with failed attempts | Each task gets fresh context |
| Memory | No persistence across sessions | Spec is persistent source of truth |
| Bug tracking | Discovered late, forgotten | Bugs become new tasks |
| Completion | No clear stopping point | Clear completion criteria |
Advanced: Multi-Session Workflows
The task system supports coordination across multiple Claude Code sessions. Set a shared task list ID:
CLAUDE_CODE_TASK_LIST_ID=myproject claudeOr add to .claude/settings.json:
{
"env": {
"CLAUDE_CODE_TASK_LIST_ID": "myproject"
}
}One session acts as orchestrator; another becomes a checker that monitors completed tasks, verifies implementation quality, and adds follow-up tasks for anything missing.
When to Use This Workflow
This pattern excels for:
- Large refactors touching many files
- Migrations requiring research into external codebases
- Feature implementations with unclear requirements
- Learning new libraries by studying their source
It’s overkill for:
- Small bug fixes
- Single-file changes
- Well-defined, simple features
The Tools You Need
- Claude Code CLI (latest version with task tools)
- A spec document (markdown works great)
- Reference codebases if learning from existing implementations
- Git for atomic commits
Further Reading
- Beads Steve Yegge’s git-backed issue tracker that inspired the task system
- 12 Factor Agents Design principles for AI coding agents
- Building Effective Agents Anthropic’s research on agent architectures
- For a broader overview of Claude Code’s feature stack, see my comprehensive guide Understanding Claude Code's Full Stack: MCP, Skills, Subagents, and Hooks Explained A practical guide to Claude Code's features — explained in the order they were introduced: MCP (2024), Claude Code core (Feb 2025), Plugins (2025), and Agent Skills (Oct 2025). What each does, how they fit together, and when to use what.
Conclusion
Spec-Driven Development with Claude Code mirrors real engineering workflows: parallel work, handoffs, blockers, and dependencies. Instead of treating Claude as a solo coder, you treat it as a team.
The key insight from Beads applies here:
“By having each task that you give a coding agent isolated into its own context window, you can now give it the ability to log any bugs for later.”
The SQLite to IndexedDB migration would have taken me 2-3 days manually. With this workflow, it took one afternoonand produced better code thanks to the research phase uncovering patterns from Jazz I wouldn’t have found on my own.
Try it yourself: Start your next significant feature with “write a spec for X, spin up subagents for research” and see how it changes your workflow.