✨TLDR
- →1–3 story-point tickets fit in one Opus 4.7 or GPT 5.5 shot. 5+ pointers don't. The context fills, the model auto-compacts, and the refactor never happens.
- →AFK coding is HITL at the edges, AFK in the middle. You align on the spec, you review the PR. Everything between runs without you.
- →The pipeline: spec → vertical-slice sub-tickets → Ralph loop per slice with TDD red-green-refactor → dedicated refactor pass → agent-browser QA → PR.
- →You're a manager now: review, QA, and several pipelines in parallel.
The Pipeline
The workflow I use to ship a 5-point ticket while I’m away from the keyboard:
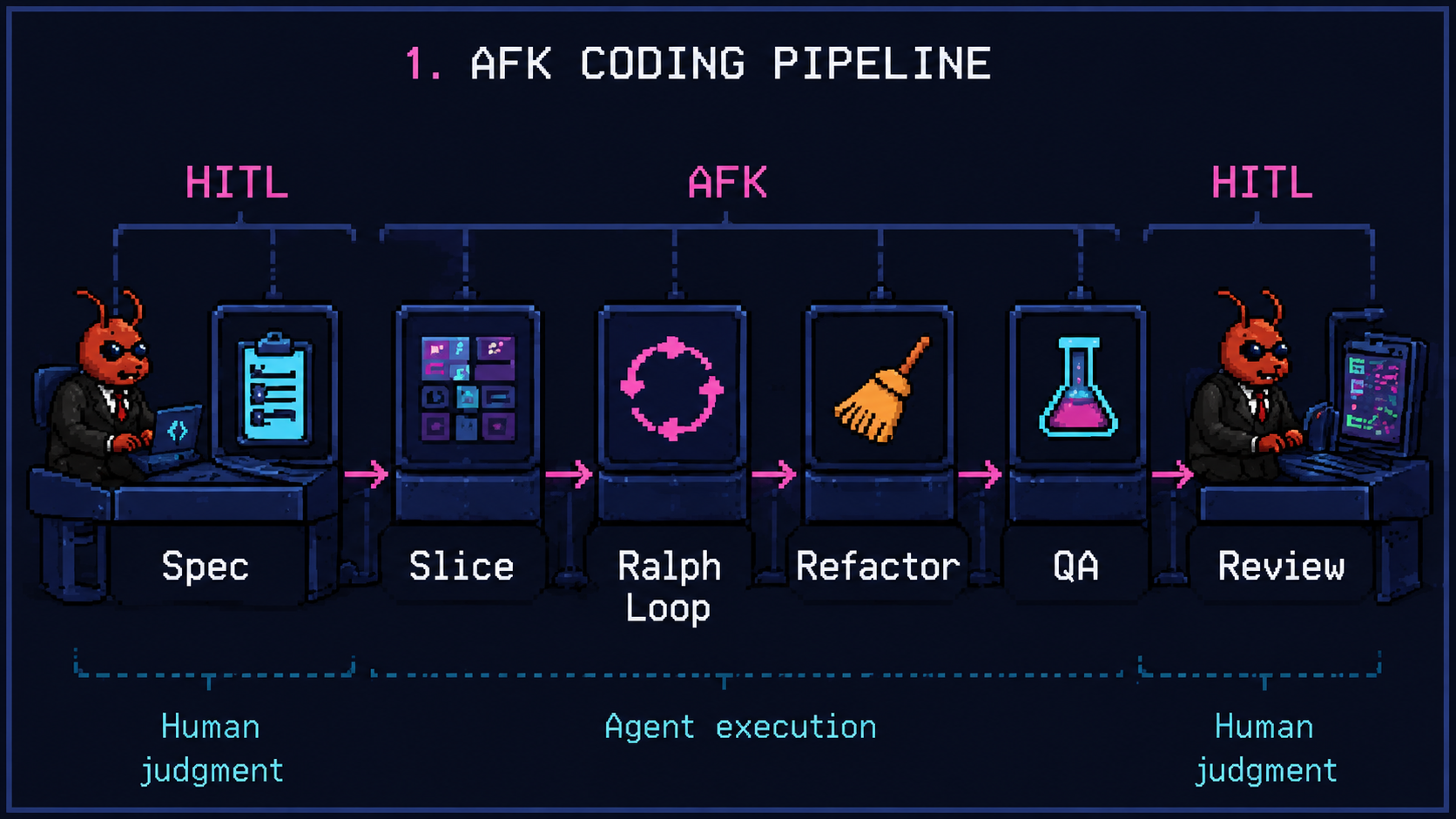
Six phases. The first and last are human, the middle four run on their own.
1. Align on spec ── HITL ── business + dev + AI interviewer
2. Slice the ticket ── AFK ── vertical slices, one per sub-ticket
3. Ralph loop per slice ── AFK ── fresh context, TDD red-green-refactor
4. Refactor pass ── AFK ── the step LLMs always skip
5. Agentic QA ── AFK ── agent-browser drives the real UI
6. Review ── HITL ── dev reviews, business does UATTwo questions first: when this pipeline pays off, and what “AFK” looks like in practice.
Two Kinds of Tickets

Most tickets fit in one Claude Code session. Paste it in, watch it land, ship the PR. Opus 4.7 or GPT 5.5 close out a 1–3 pointer with maybe one nudge. No pipeline needed.
The interesting tickets are the 5-pointers. Frontend and backend, a multi-step wizard with three API calls, server-side validation, optimistic UI, and a test plan that catches the failure modes you care about. Paste that into a fresh chat and one of three things happens:
- Context runs out. The model hits the window halfway through and auto-compacts. The summary drops the bit you needed. As HumanLayer’s 12 Factor Agents puts it: “Even as models support longer and longer context windows, you’ll ALWAYS get better results with a small, focused prompt and context.”
- No refactoring. LLMs default to append, not restructure. Ship five of these in a row and your codebase looks like the inside of a hoarder’s garage.
- Silent skip. When a test fails on round four, the model deletes the test rather than fixing the bug. Opus does this often. Michael Arnaldi caught it taking the same shortcut in his Effect workshopVibe Engineering Effect Apps: Just Clone the RepoMichael Arnaldi's workshop on building Effect apps with coding agents. The single trick: clone the library repo as a git subtree so the agent reads source code instead of fighting stale docs.: “sometimes a feature, sometimes a bug — takes shortcuts, sleeps, removes failing tests rather than fixing them.”
This is a workflow problem, not a model problem. Big tickets need a pipeline, not a prompt. The one diagrammed above.
What AFK Coding Looks Like
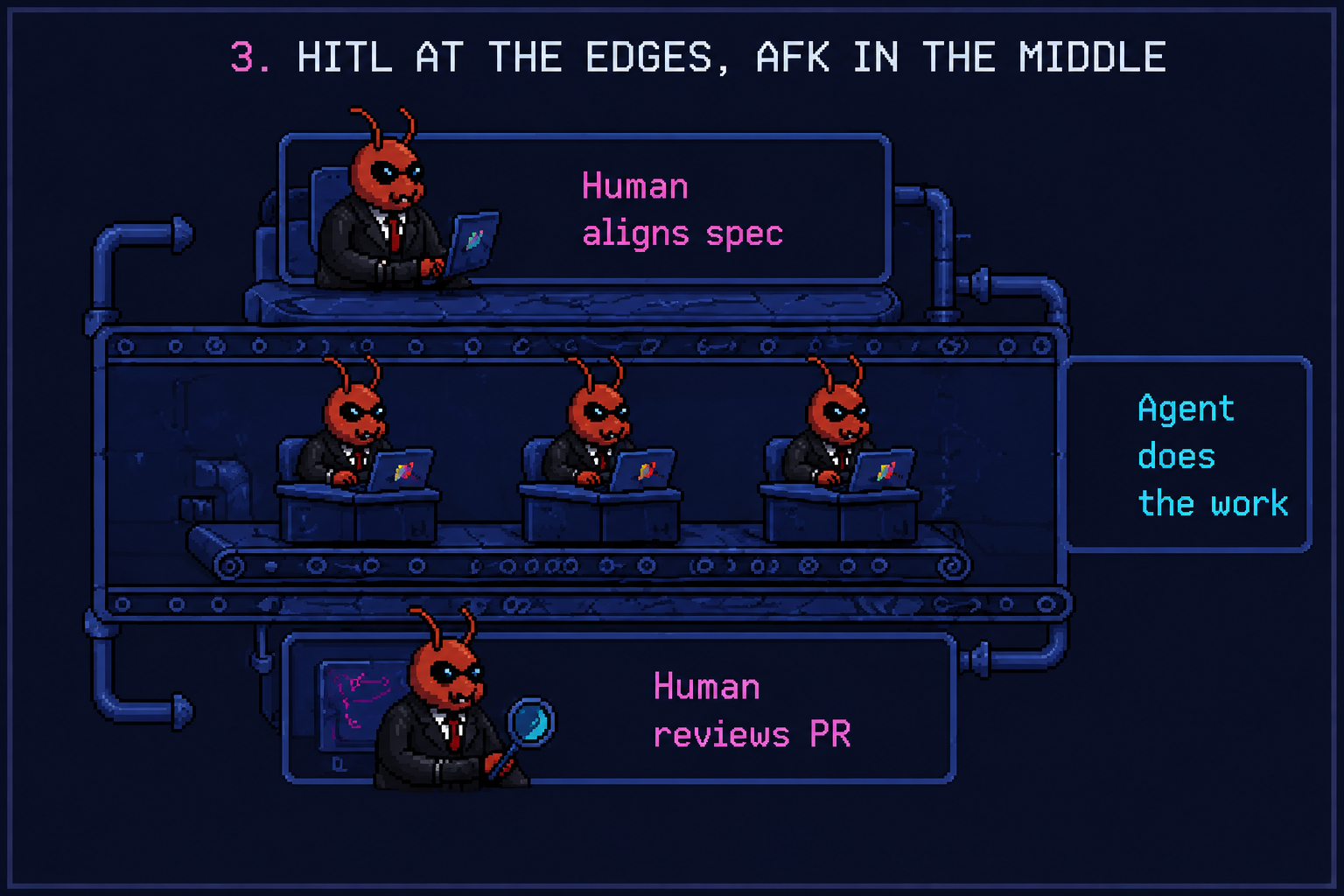
AFK = away from keyboard. HITL = human in the loop. Sounds opposed; isn’t. The good workflow is HITL at the edges, AFK in the middle.
- HITL up front. A human aligns on what to build. Judgment lives here.
- AFK in the middle. Once the spec is solid, the agent ships it. You go for a walk.
- HITL at the end. Review the PR, eyeball the QA report, ship.
You don’t write less code. You run three pipelines in parallel while reading a book. You manage instead of coding. I wrote about the broader shift in The Software FactoryThe Software Factory: Why Your Team Will Never Work the Same AgainWe already have everything we need to build software factories. Teams will change. The only variable is speed.; this post zooms into the pipeline that powers a single ticket inside it.
Phase 1: Align on the Spec (HITL)
Don’t skip this. Every problem downstream starts here. Dex Horthy puts the cost in stark terms in Advanced Context Engineering for Coding Agents:
“A flawed specification cascades through hundreds of lines; flawed research generates thousands of bad lines.”
A 5-pointer touches enough surface area that “what we want” needs to be explicit. Sit with the business, talk through the wizard, draw the state machine on a napkin. Then write a real PRD. A Jira description doesn’t count.
Use the AI here too, but in interview mode, not generation mode. Open Claude Code with a spec template and let it ask you the questions you’d otherwise forget:
i want to build a multi-step booking wizard. interview me with one question at a time until you have enough to write a PRD. cover: goals, user, happy path, edge cases, validation, error states, and out-of-scope. write the PRD to docs/prd-booking-wizard.md when done.
The PRD is the single artifact the rest of the pipeline reads. Skimp here and the agent will ship the wrong thing five times in parallel. Spec-Driven Development with Claude Code in ActionSpec-Driven Development with Claude Code in ActionA practical workflow for tackling large refactors with Claude Code using parallel research subagents, written specs, and the new task system for context-efficient implementation. covers the prompt patterns I lean on; GitHub’s Spec Kit ships a four-phase /specify → /plan → /tasks → /implement workflow that encodes the same idea if you’d rather not roll your own.
Phase 2: Slice Into Vertical Tickets (AFK)
The PRD is too big for one Ralph loop. Slice it.
The right unit isn’t “frontend task” + “backend task” + “tests task.” That’s a horizontal slice, and horizontal slices kill agents. Every slice needs every other slice to be useful, so nothing works until everything works. Compaction guaranteed.
A vertical slice is a thin end-to-end strip of behaviour: one API endpoint, the one form step that consumes it, and the one test that proves it works. Each vertical slice is independently shippable. Each one fits in a Ralph loop. Each one survives if its sibling slice fails.
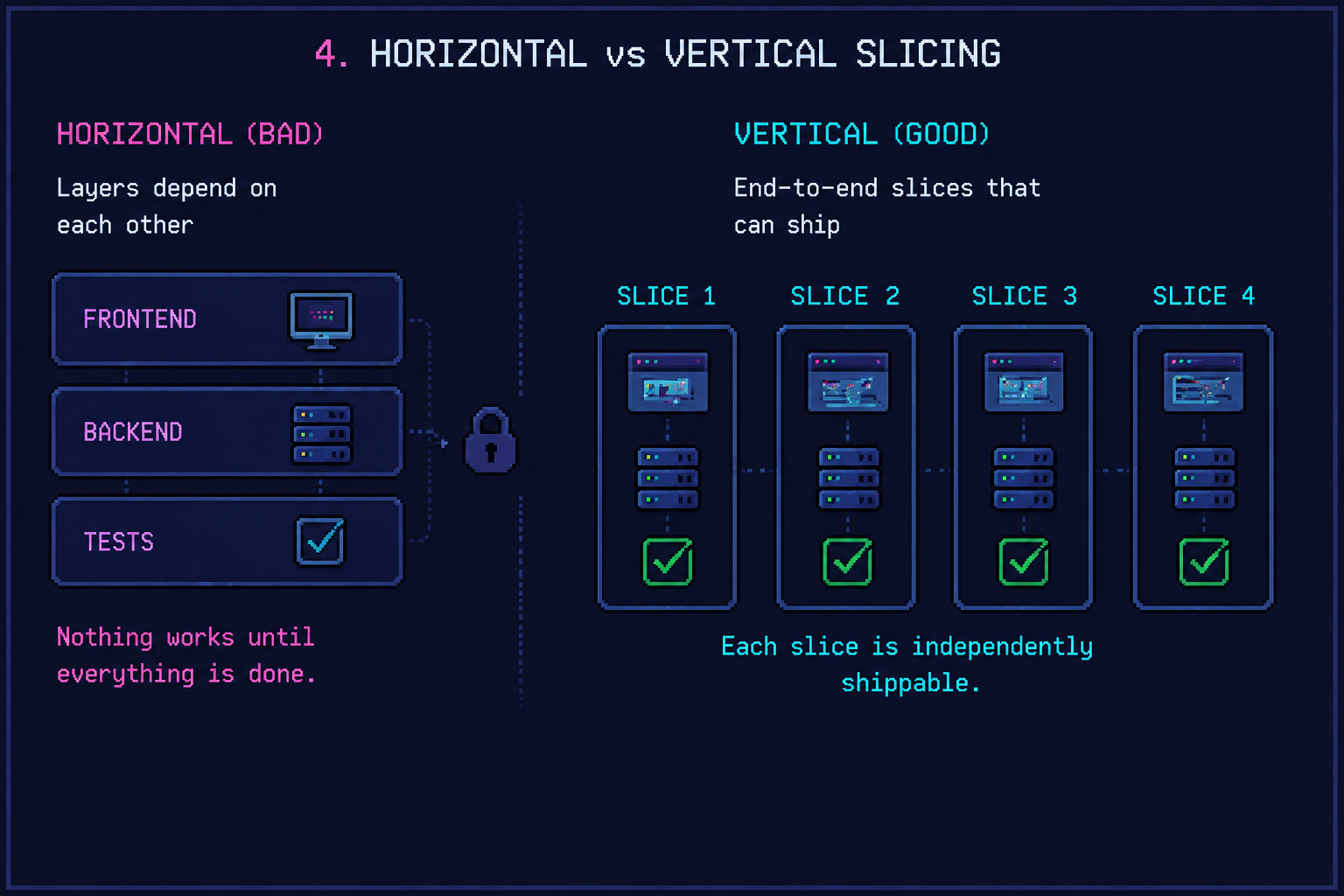
This is Factor 10 of 12 Factor Agents applied to ticket scoping: “Small, focused agents — keep agents to 3–20 steps; avoid monolithic designs.” A vertical slice is the ticket-shaped equivalent. Steve Yegge frames the alternative bluntly in 2026: The Year The IDE Died:
“Nature builds ant swarms and Claude Code built this huge muscular ant that’s just going to bite you in half and take all your resources.”
For our wizard:
Slice 1: Step 1 — guest info (form + POST /booking/draft + e2e test)
Slice 2: Step 2 — room selection (form + GET /rooms + e2e test)
Slice 3: Step 3 — payment (form + POST /booking/confirm + e2e test)
Slice 4: Wizard state machine (cross-step navigation + e2e test)Four sub-tickets. Each is a 1–2 pointer. Each is something Opus 4.7 can ship in one go.
Have the agent do the slicing for you:
read docs/prd-booking-wizard.md. break it into vertical slices. each slice must be end-to-end (UI + API + test) and independently shippable. write the slices to docs/tickets/01-.md, 02-.md, …
Phase 3: Ralph Loop Per Slice (AFK)
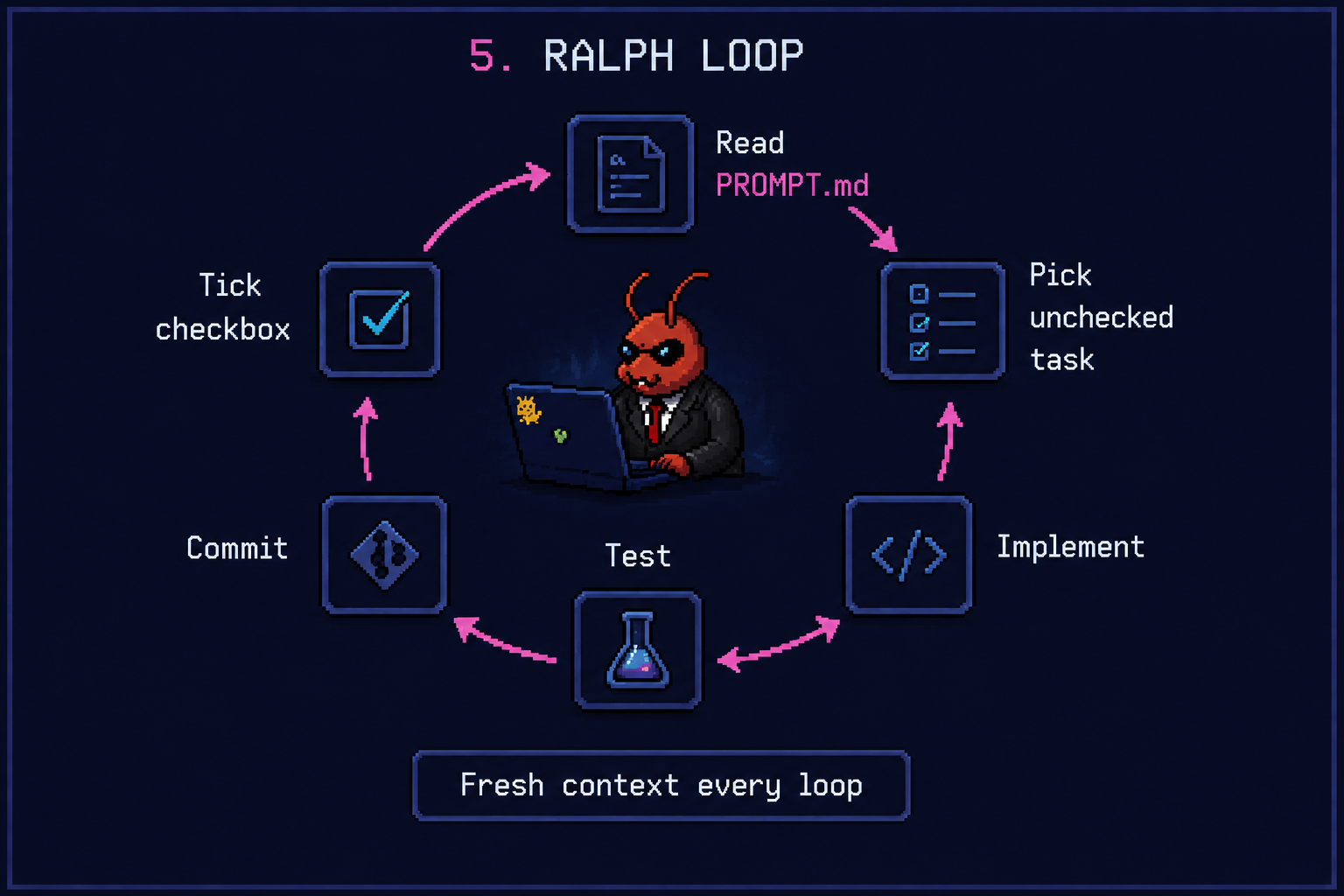
For each slice, spin up a fresh agent in a Ralph loop.
Ralph is Geoffrey Huntley’s technique: a while loop that pipes a prompt file into a fresh claude invocation, over and over, until a stopping condition trips. Every iteration starts with an empty context, reads the prompt file, picks the highest-priority unfinished task, ships it, commits, and exits.
while :; do
cat PROMPT.md | claude --dangerously-skip-permissions
doneHuntley’s framing of why it works:
“That’s the beauty of Ralph — the technique is deterministically bad in an undeterministic world.”
You aren’t aiming for one perfect run. You’re aiming for many cheap runs that converge, with the prompt file as the ratchet. He shipped six repos overnight at a YC hackathon and replaced a $50K outsourcing contract with $297 of API spend.
The reason the loop works is the one Dex Horthy chronicles in A Brief History of Ralph: context windows degrade as they fill. Resetting between iterations keeps every task in the model’s “smart zone.” Factory’s write-up on The Context Window Problem makes the same case from the engineering side. Bigger windows aren’t the answer; smaller scopes are.
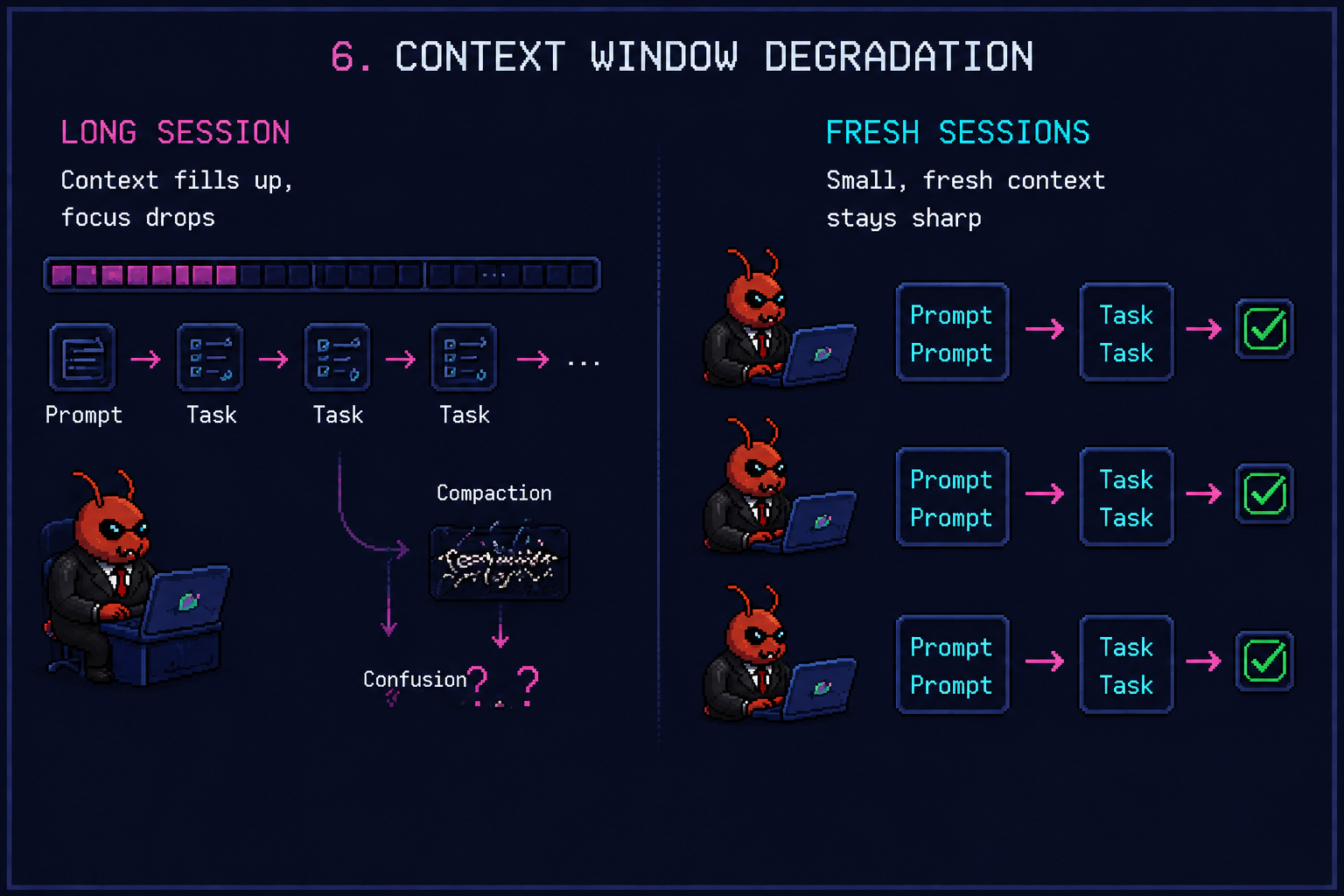
A small driver script gives each slice its own Ralph instance, in its own git worktree, with its own log file:
for ticket in docs/tickets/*.md; do
name=$(basename "$ticket" .md)
git worktree add "../wt-$name" -b "feat/$name"
(
cd "../wt-$name"
cp "$ticket" PROMPT.md
while :; do
cat PROMPT.md | claude --dangerously-skip-permissions
grep -q "^- \[ \]" PROMPT.md || break # exit when no unchecked items
done
) &
done
waitFour slices, four worktrees, four agents, in parallel. Matt Pocock’s Sandcastle (covered here) is the productionised version of this, with sandboxing on top so the agents can’t rm -rf your home directory. The cautionary tale is real. See Claude Code is Amazing… Until It DELETES Production. YOLO mode without a sandbox is how you wake up to an empty home folder.
TDD Inside the Loop
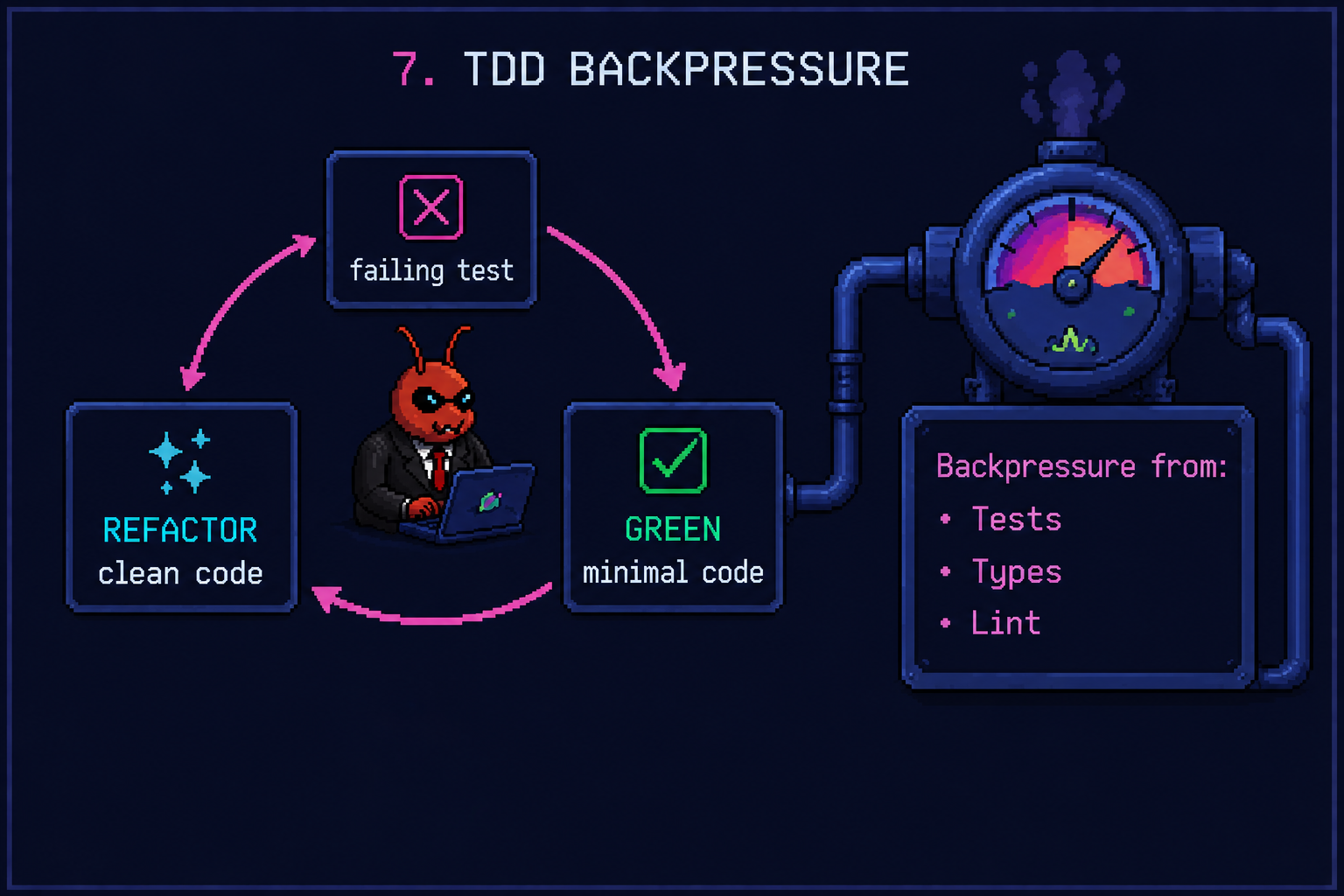
The Ralph prompt for each slice forces red-green-refactor inside every iteration:
you are working on ONE slice. read PROMPT.md.
for each unchecked task:
- red: write a failing e2e test that asserts the behaviour
- green: write the minimum code to pass the test
- refactor: clean up; tests must stay green
- commit
- tick the box in PROMPT.md exit when all boxes are ticked.
Two reasons TDD matters more for AFK agents than for humans:
- Without tests, the agent rips the feature out and you never notice. A passing test it didn’t write is a contract; a green CI is the agent’s permission slip to commit.
- Red-green-refactor is the only refactor the agent will do without supervision. Even that’s not enough in practice. That’s why Phase 4 exists.
Moss Ebeling calls this back pressure: automated feedback that lets the agent self-correct without you in the loop. If your tests, types, and lint don’t break when something is wrong, the agent doesn’t know it’s wrong. Every minute you spend tightening backpressure is a minute you don’t spend reviewing trivial mistakes by hand.
Phase 4: Refactor Pass (AFK)
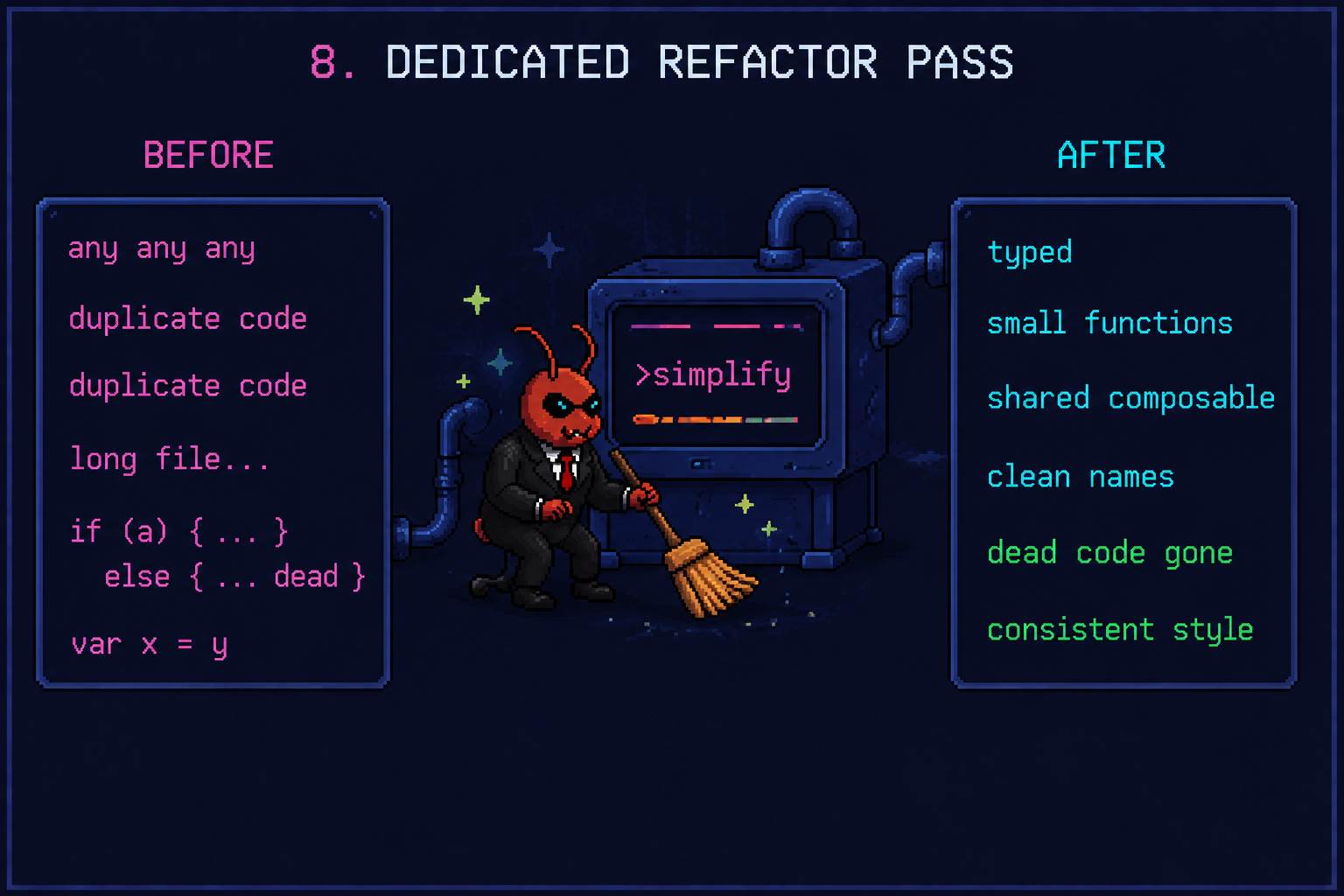
LLMs cheat on refactoring. Even with red-green-refactor in the loop, the “refactor” step usually shrinks to “rename a variable.” The deeper work (extracting a composable, collapsing duplication across the four slices, killing the dead branches) never happens. Leave a single any lying around and Opus will copy it everywhere (Arnaldi’s observation).
This is why I built /simplify: a Claude Code skill that runs an Opus subagent over the recently changed files with one job. Clean it up without changing behaviour. Tests stay green, naming improves, ternaries unfold, abstractions collapse. It’s the dedicated refactor pass the implementation loop won’t do on its own. It ships as a Claude Code skill, but the pattern is portable — if you’re on Codex or another agent, you can wire up the same thing yourself.
Run it as a separate agent against the merged branch with a narrower brief:
run on the current branch. tests must stay green throughout.
for each of: duplication, long files, primitive obsession, dead code, and inconsistent naming — find one offender, fix it, run tests, commit. repeat until you can’t find more.
do not change behaviour. do not add features.
Then add lint-as-backpressure rules so the next slice doesn’t undo the cleanup. My ESLint setupMy Opinionated ESLint + Oxlint Setup for Vue ProjectsA battle-tested linting configuration that catches real bugs, enforces clean architecture, and runs fast using Oxlint and ESLint together. covers the rules I lean on; Michael Arnaldi’s “clone the repo” workflowVibe Engineering Effect Apps: Just Clone the RepoMichael Arnaldi's workshop on building Effect apps with coding agents. The single trick: clone the library repo as a git subtree so the agent reads source code instead of fighting stale docs. takes the same idea further. Every shortcut you catch the agent taking, ban it with a rule.
Phase 5: Agentic QA (AFK)
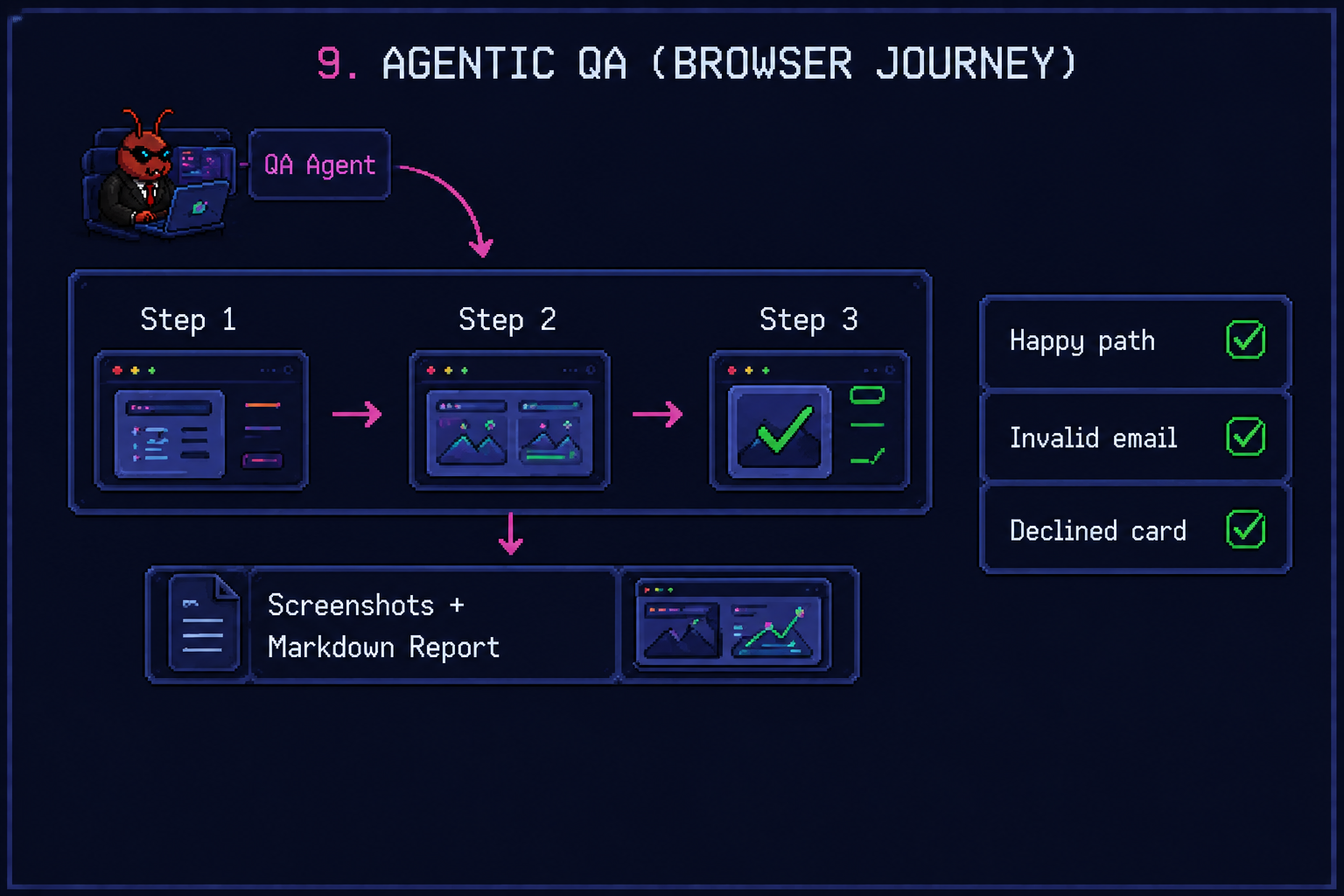
Tests prove the unit works. They don’t prove the user can complete the wizard. For that, drive a real browser.
agent-browser is a Rust CLI that exposes the browser’s accessibility tree as a snapshot with stable element refs (@e1, @e2, …). The agent reads the snapshot, picks a ref, and clicks. No CSS selectors, no Playwright API to learn. Shell commands the agent already knows how to run.
A QA agent runs the user journey end-to-end:
you are a QA engineer. the booking wizard is at localhost:3000/book.
run the happy path: complete all three steps with valid data. then run two negative paths: invalid email at step 1, declined card at step 3.
use agent-browser. take a screenshot at every state. write a markdown report to qa/booking-wizard.md with one section per test: steps taken, expected, actual, pass/fail, and the screenshot.
You wake up to a markdown report with screenshots. If anything is red, the report tells you which step. If everything is green, the PR is ready for human eyes.
Phase 6: Human Review (HITL)
The agent opens the PR. Now you do the job.
- Dev review. Read the diff. Read the test names. Do they describe behaviour the user cares about? Run the app locally for ten minutes. The bar is “would I have shipped this myself,” not “did the agent do what I asked.”
- Business UAT. Send the PR’s preview URL to the person who wrote half the PRD with you. They click through the wizard. They find the thing the agent never could have known to check.
The 30 minutes on the spec and the 30 minutes on the review are 80% of the value. The four hours of coding in between are the part you outsourced. As Linear frames it in their agent SDK approach: “An agent cannot be held accountable.” Issues get delegated to agents but assigned to humans. Review is the part of the job that doesn’t have an AFK version.
Why This Pipeline Beats “Just Use a Bigger Model”
You could wait for the next model with a 10M-token window and pretend the problem goes away. It won’t. Bigger windows degrade: attention thins, costs balloon, and the model still won’t refactor on its own.
The pipeline is mostly the work humans always did, automated:
- A spec, because nobody ships a 5-pointer without one.
- Vertical slices, because Mike Cohn was right about user stories twenty years ago.
- TDD, because red-green-refactor is the only loop that catches regressions cheaply.
- Code review, because two pairs of eyes are still better than one set of weights.
- QA, because tests don’t catch UX.
What changed: the typing happens AFK. You only show up where judgment lives.
When to skip the pipeline
For 1–3 pointers, skip all of this. One Claude Code session, one prompt, one PR. The pipeline is overhead for small work; it pays back at 5 points and up.
The Job Changes
A developer’s day in this model:
- 30 minutes: interview-driven spec for ticket A
- 5 minutes: kick off Ralph loops for ticket A
- 30 minutes: interview-driven spec for ticket B
- 5 minutes: kick off Ralph loops for ticket B
- 1 hour: review yesterday’s PR, check the QA report
- Repeat
You’re a manager of a small fleet of agents. Each ticket is a project; each Ralph loop is a contractor. The skill is your specs, your reviews, and your taste, not your typing speed.
This isn’t theoretical. Boris Cherny, creator of Claude Code, runs 15+ parallel Claude sessions on a normal day: five in numbered terminal tabs and another five-to-ten on claude.ai/code, with iTerm notifications when one needs input. Anthropic’s headcount tripled and productivity per engineer climbed 70%. Roughly 80–90% of Claude Code is now written by Claude Code itself.
Lee Robinson, after building three production projects without writing code by hand, puts it bluntly:
“Writing code was never really the bottleneck, especially for larger projects.”
Boris reaches the same conclusion from inside Anthropic:
“We’re going to start to see the title of software engineer go away. It’s just going to be ‘builder’ or ‘product manager.’”
The pipeline isn’t novel. Stripe’s Minions, Steve Yegge’s Gas Town, Pocock’s Sandcastle all encode variants of it. The novel part: the building blocks (Claude Code in headless mode, agent-browser, Ralph, git worktrees) are open and free. You can run this pipeline tonight on your own machine.

Don't run twenty pipelines because you can
Simon Willison flagged the dark side of all this in AI Doesn’t Reduce Work — It Intensifies It: the low cost of “just one more prompt” turns into compulsive task-stacking and burnout. The point of AFK coding is to be away from the keyboard, not to triple-book your attention. Run as many pipelines as your review capacity can absorb. Not more.
Conclusion
- Small tickets fit a single chat. 5-point tickets need a pipeline.
- The pipeline is HITL up front, AFK through spec → slice → Ralph loop with TDD → refactor → agentic QA, HITL at review.
- Vertical slices keep each Ralph loop in the model’s smart zone and survive partial failure.
- Refactor needs its own dedicated pass. The agent won’t do it inside the implementation loop.
- Agent-browser closes the gap between “tests pass” and “the user can finish the wizard.”
- Run several pipelines in parallel. You’re managing now, not typing.
Further reading
The notes I leaned on for this post, grouped by what they support:
- Why a pipeline beats a prompt: 12 Factor Agents · The Context Window Problem · Advanced Context Engineering for Coding Agents
- Spec phase: Spec-Driven Development with AI · A Practical Guide to Writing Technical Specs · Spec-Driven Development with Claude Code in ActionSpec-Driven Development with Claude Code in ActionA practical workflow for tackling large refactors with Claude Code using parallel research subagents, written specs, and the new task system for context-efficient implementation.
- Ralph loop: Ralph Wiggum as a Software Engineer · A Brief History of Ralph · Stop Chatting with AI. Start Loops.
- TDD + backpressure: Essential AI Coding Feedback Loops for TypeScript Projects · Don’t Waste Your Back Pressure
- Refactor pass: Vibe Engineering Effect Apps (Michael Arnaldi)
- QA: agent-browser · Claude Code is Amazing… Until It DELETES Production
- The job changes: Boris Cherny on building at Anthropic · AI codes better than me. Now what? · 2026: The Year The IDE Died · I Open-Sourced My Own AFK Software Factory · The Software FactoryThe Software Factory: Why Your Team Will Never Work the Same AgainWe already have everything we need to build software factories. Teams will change. The only variable is speed.
- The caveat: AI Doesn’t Reduce Work — It Intensifies It