Motivated by the awesome YouTube video from Andrew Karpathy How I use LLMs, I decided to give two talks on how I use LLMs, both at my company and at the TypeScript meetup in Munich.
This blog post is the written version of those talks.
Keep in mind that while some things might change, especially regarding the models I currently use, I hope these tips will remain helpful for a long time.
As a junior developer, you might think your job is all about coding. However, as you gain experience, you realize that’s not entirely true. We developers spend a significant amount of time learning new things or explaining concepts to others. That’s why, when it comes to using LLMs, we shouldn’t focus solely on code generation.
We should also consider how to:
- Research faster
- Document better
- Learn more effectively
Most of my tips won’t be about how to use Cursor AI or Copilot better. I think that would be worth its own blog post or a short video.
Which model should I choose
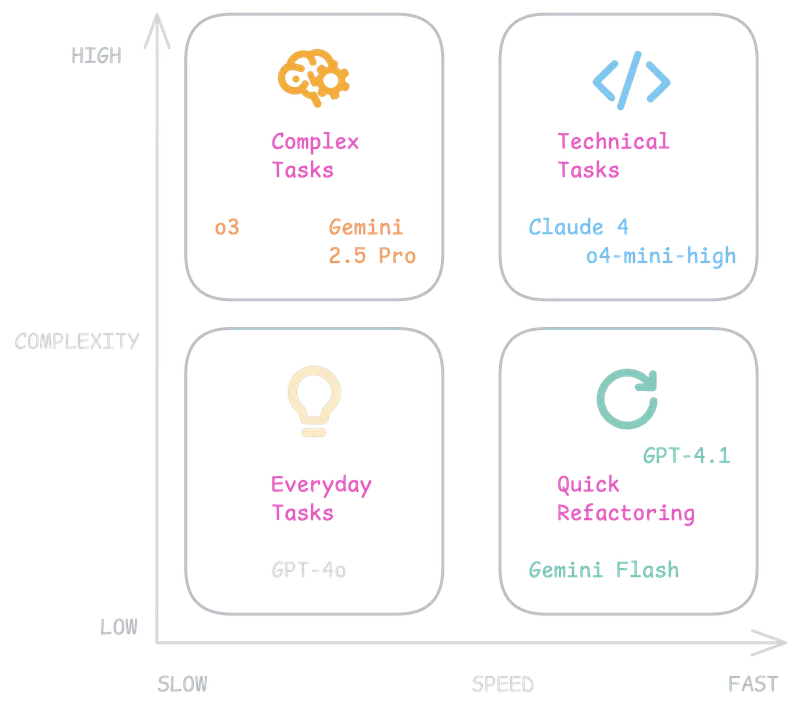
It’s annoying that we even have to think about which model to use for which task. I would guess that in the future (Cursor AI is already doing this), there will be a model as a kind of router in the middle that understands which prompt relates to which model.
But for now, this isn’t the case, so here’s my guideline. In the picture, you see that I came up with four categories:
- Everyday tasks (like fixing spelling, writing something better)
- Quick Refactoring (like adding console logs to debug something, small refactorings)
- Technical Tasks (like doing research)
- Complex Tasks (tasks that definitely need long reasoning and thinking)
It’s important for me, since I don’t have an unlimited amount of o3, for example, to try to use o4-mini-high if I think I don’t need long reasoning for something.
As I said, these models will change daily, but I think the categories will remain.
So most of the time, I ask myself if I need a model that requires reasoning or not.
o3 is a mini agent
What’s also clear is that new models like o3 are mini agents. This means they’re not only predicting the next token but also have tools. With these tools, they can gain better context or perform operations with Python.
This is why Simon Willison’s blog post explains how he used o3 to guess his location. As his title says: Watching o3 guess a photo’s location is surreal, dystopian, and wildly entertaining, but it also shows how powerful this can be. Read his blog post here.
I also wrote a blog post once where I gave o3 a hard chess puzzle to solve. Feel free to read it here.
Some tips on how to get more out of Copilot and co
My first tip is to index your codebase, either with a local index or remote. With this, Cursor or Copilot can perform better searches.
It all falls back to automatic retrieval. Keep in mind that an LLM doesn’t know where your files are located. So it always has to search against your codebase.
One technique besides keyword search that can help is dense vector or embedding search. You can read the docs on how to implement that.
Another tip: when you have a project that’s indexed, you can use Copilot’s ask mode and use @workspace. Now you can ask business questions or even solve simple tickets in one shot (if there are well-written tickets). For more information on how to index your repositories for Copilot Chat, refer to the GitHub Copilot documentation.
My last tip, where I use Gemini 2.0 Flash or GPT-4.1, is to do little refactorings or code changes quickly. I quickly mark the related lines and then use a prompt to make the changes.
How can we improve the output of an LLM
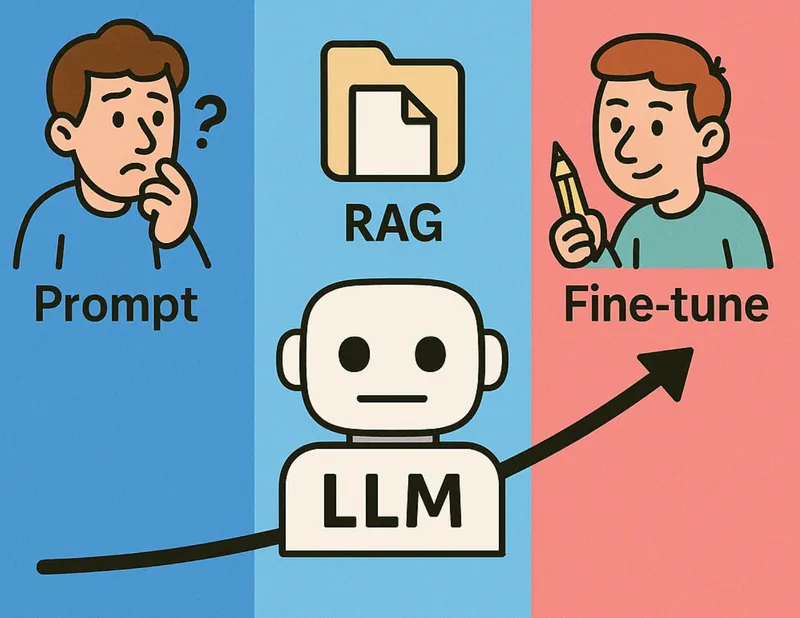
In the book “AI Engineering” by Chip Huyen, she explains that there are three main ways to improve the output of an LLM:
- With Prompts
- Per RAG
- With fine-tuning
Of course, all three ways will increase in effort and maybe ROI, but it’s clear that better prompts are always the first step to improving the output of an LLM.
The almighty System Prompt
The idea of a System Prompt is simple but genius. We change the default behavior of an LLM and customize it to our needs.

In the picture, you see an example of a system prompt that I use to write blog posts.
In the picture, you see an example of a system prompt that can be used to write Jira tickets. At work, I have something like that and use it together with Copilot. My goal is to quickly write what needs to be done, and the LLM handles the rest. It also asks questions when something is not clear.
You can use that for many problems, and also keep in mind that every LLM provider, like OpenAI or Claude, has their own system prompt. One use case, for example, is to explain which tools an LLM has available, etc. At GitHub, you can read some of the leaked system prompts.
This is why this is a good structure to think about when you write system prompts:
- Role Definition
- Step-by-Step Instructions
- Output Format
- Edge Cases
- Style Guidelines
When you tell the LLM which role it has, it will already use words and tokens that are useful for this role in its next prediction.
Clear steps can help for a more complex workflow so the LLM knows when it’s done, etc.
For something like a Jira ticket, we should also add a concrete output format with an example.
In my experience, edge cases are something that you will add over time. We need to play with the LLM and see what vibe we get from it.
Style guidelines are useful. For example, I love easy words and active voice.
You can also ask the LLM how a system prompt should look for the problem you want to solve and use that as your version 1. This approach can provide a solid starting point for further refinement.
Googling is dead
Don’t get me wrong, I think Google is winning the AI arms race. As noted in The Algorithmic Bridge, Google is excelling on every AI front. But the classical googling, where we typed a query and the first five results had an ad and it was hard to find an organic result, is over.

Most of the time, I use a reasoning model with a web search tool. This helps me as a starter to find related blog posts, etc., for my problem. I only use Google when I know the site I want to reach or I know which blog post I want to read.
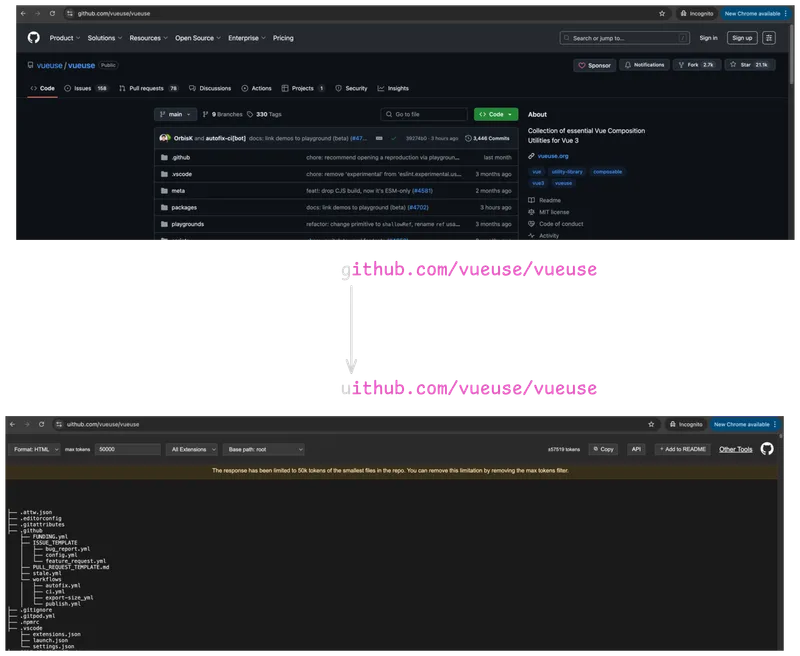
Get all tokens out of a repo
If you change GitHub to Uithub for any repo, you will get all text in a way that you can just copy-paste it into a model with a high context, like Google Gemini.
This can be useful to either ask questions against the codebase or to learn how it works or to rebuild something similar without needing to increase the depth of your node modules.
Generate a Wiki out of any repo
When you go to https://deepwiki.org/, you can generate a wiki out of any repo. Useful for understanding other repos or even for your own little side projects. What I like is that the LLMs generate mermaid diagrams, and sometimes they are really useful.
Generate diagrams
I think there are now three ways to generate good diagrams with an LLM:
- As SVG
- As Mermaid
- Or as a picture with the new model
I already wrote about how to use ChatGPT to generate mermaid diagrams. Read it here.
Rules Rules Rules
We human developers need rules, and the same is true for LLMs to write better code. This is why both Copilot and Cursor have their own rule system. For detailed information on how to set up and use rules in Cursor, check out the official Cursor documentation on rules.
One idea when you have a monorepo could be something like this:
my-app/
├── .cursor/
│ └── rules/
│ └── project-guidelines.mdc # General code style, naming, formatting
├── frontend/
│ ├── .cursor/
│ │ └── rules/
│ │ ├── vue-components.mdc # Naming + structure for components
│ │ └── tailwind-usage.mdc # Utility-first CSS rules
│ └── src/
│ └── ...
├── backend/
│ ├── .cursor/
│ │ └── rules/
│ │ ├── api-structure.mdc # REST/GraphQL structure conventions
│ │ └── service-patterns.mdc # How to organize business logic
│ └── src/
│ └── ...
├── shared/
│ ├── .cursor/
│ │ └── rules/
│ │ └── shared-types.mdc # How to define + use shared TypeScript types
│ └── src/
│ └── ...
├── README.md
└── package.jsonOne rule could then look like this:
---
description: Base project guidelines and conventions
globs:
- "**/*.ts"
- "**/*.vue"
alwaysApply: false
---
- **Use `PascalCase` for component names.**
- **Use `camelCase` for variables, functions, and file names (except components).**
- **Prefer composition API (`setup()`) over options API.**
- **Type everything. Avoid `any` unless absolutely necessary.**
- **Keep files under 150 LOC. Split logic into composables or utilities.**
- **Use absolute imports from `@/` instead of relative paths.**
- **Every module must have tests that reflect the feature's acceptance criteria.**
- **Commit messages must follow Conventional Commits format.**
- **Use TODO: and FIXME: comments with your initials (e.g., `// TODO: refactor`).**
- **Format code with Prettier. Lint with ESLint before committing.**
Referenced files:
@.eslintrc.js
@.prettierrc
@tsconfig.jsonThis is an example for Cursor. The idea is to give a more fine-grained context. In our example, maybe it would even be better to only have a .vue and separate .ts rule.
In Agent mode, Cursor will then automatically apply this rule as context.
Write better image prompts
One technique that I think can be useful is to describe which image you want and then say, “give me that back as a Midjourney prompt.” This has the advantage that the description of the image is nicely formatted.
When should you use an LLM directly
An interesting question that I got from the TypeScript meetup was when I would directly vibe code and just tell Cursor to implement feature X and when not.
In my experience, it all depends on the topic and how much training data is available for that.
For example, last week I was using Nuxt together with NuxtUI, a good UI library for Nuxt, but the problem was that the LLM doesn’t understand how the components are structured, etc. So in that case, it would be better if I were the main driver and not the LLM.
So always ask yourself if there is enough training data out there for your problem. Was it already solved in the past?
Sometimes you will waste time by just blindly doing vibe coding.
Summary
There are many ways we developers can use LLMs to be more productive and also have more fun. I believe most of us don’t want to spend too much time writing tickets. This is where LLMs can help us. I believe it’s important to be open and try out these tools.
If you want to get better with these tools, also try to understand the fundamentals. I wrote a blog post explaining how ChatGPT works that might help you understand what’s happening under the hood.